사전 준비
- 이미 Spring Boot + MySQL로 간단한 게시판 서비스를 만들어 놓은 상태로 실습을 진행하였습니다.
- Elasticsearch와 Kibana는 둘 다 Elastic의 공식 Docker 이미지를 제공하며, Docker Compose를 사용하면 두 컨테이너를 쉽게 구성하고 실행할 수 있습니다.
- 저는 로컬 환경에 도커 이미지를 받아 컨테이너 띄워서 실습을 진행하였습니다
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.5.0
container_name: elasticsearch
environment:
- node.name=elasticsearch
- discovery.type=single-node
- bootstrap.memory_lock=true
- ES_JAVA_OPTS=-Xms512m -Xmx512m
- xpack.security.enabled=false # 기본으로 보안 설정 비활성화 (로그인 및 HTTPS 없이 시작)
- xpack.security.transport.ssl.enabled=false
- ELASTICSEARCH_PASSWORD="비밀번호"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es_data:/usr/share/elasticsearch/data
ports:
- "9200:9200"
networks:
- elastic
kibana:
image: docker.elastic.co/kibana/kibana:8.5.0
container_name: kibana
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
ports:
- "5601:5601"
networks:
- elastic
volumes:
es_data:
driver: local
networks:
elastic:
driver: bridgedocker-compose 파일입니다.


Elastic Search 실습
이제 Kibana에 접속해서 index를 생성해보겠습니다. 일단 Kibana에 대한 간단한 설명을 먼저...
Kibana?
- 주요 기능
- 데이터 시각화: 차트, 그래프, 지도, 타임라인 등
- 대시보드: 차트를 활용하여 실시간 데이터 모니터링
- 데이터 탐색(검색): Lucene와 Kibana Query Language(KQL)를 사용하여 데이터를 검색
- 경보 및 보고서: 대시보드를 기반으로 보고서 생성 및 이메일 전송
- Canvas: 사용자 지정 디자인 및 애니메이션을 포함한 인터랙티브한 데이터 시각화
- 로그 분석: Kubernates, on-premise 서버의 로그 및 metric 제공
- 보안 모니터링: 네트워크 트래픽, 시스템 로그, 보안 이벤트 등을 모니터링하여 보안 위험 탐지 및 대응
- 운영 업무:
- 서버 및 어플리케이션 리소스 모니터링
- 비즈니스 데이터를 시각화
- 운영업무(관리자, CX) 모니터링 → 당일, 전일(D-1) 조회수 상위 10개 게시글 리스트 조회
- Kibana 브라우저로 접속하기
- 5601 port로 접속하면 아래와 같은 화면을 볼 수 있습니다.

- 5601 port로 접속하면 아래와 같은 화면을 볼 수 있습니다.
Index 생성하기
우선 article이라는 index를 생성해보겠습니다
- 인덱스 생성 방법
PUT /my_index {
"settings": {
"number_of_shards": 3, // 샤드 수
"number_of_replicas": 2 // 복제본 수
},
"mappings": {
"properties": {
"title": {
"type": "text"
},
"date": {
"type": "date"
},
"price": {
"type": "float"
}
}
}
}- settings: 인덱스의 설정으로, number_of_shards와 number_of_replicas 등을 지정합니다.
- mappings: 데이터 타입과 매핑을 지정하는 부분입니다. 위 예시에서는 title은 text, date는 date, price는 float 타입으로 지정했습니다.
- 특정 필드에 사용자 정의 분석기를 적용할 수도 있습니다.
- Nori 분석기는 Elasticsearch에서 한국어 텍스트를 효과적으로 분석하기 위해 제공되는 한국어 전용 분석기입니다. 한국어는 띄어쓰기와 형태소 구조가 복잡하여 일반적인 텍스트 분석기로는 정확한 검색이 어려울 수 있는데, Nori 분석기는 이러한 한국어의 특성을 반영하여 텍스트를 처리합니다.
PUT /my_korean_index
{
"settings": {
"analysis": {
"analyzer": {
"korean_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "korean_analyzer"
}
}
}
}
저는 아래와 같은 index를 생성하였습니다
PUT /article
{
"settings": {
"analysis": {
"analyzer": {
"nori_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": [
"nori_part_of_speech",
"nori_readingform",
"lowercase",
"cjk_width"
]
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"created_date": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"modified_date": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"content": {
"type": "text",
"analyzer": "nori_analyzer"
},
"title": {
"type": "text",
"analyzer": "nori_analyzer"
},
"author_id": {
"type": "long"
},
"author_name": {
"type": "text",
"analyzer": "nori_analyzer"
},
"board_id": {
"type": "long"
},
"is_deleted": {
"type": "boolean"
}
}
}
}
article index가 생성이 되었네용
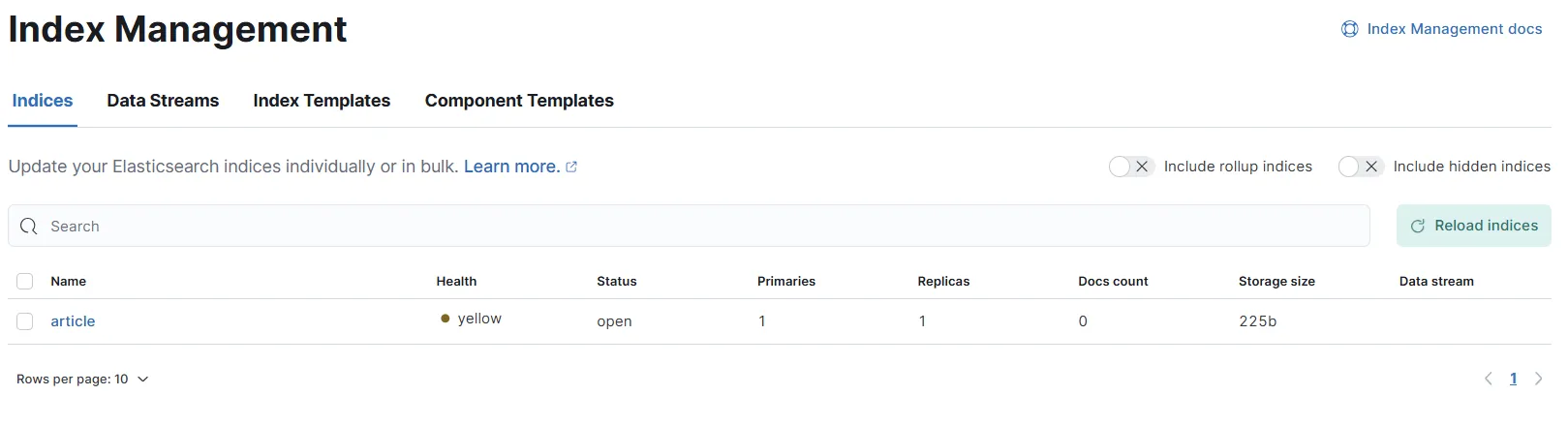
Elasticsearch의 인덱스 상태가 yellow인 이유는 보통 replica shard의 할당 문제 때문입니다. 상태가 yellow일 때, primary shard는 정상적으로 할당되었지만 복제본 샤드가 일부 할당되지 않았다는 것을 의미합니다.
저는 로컬에서 간단한 실습을 먼저 진행하고 있는 것이기 때문에 현재 노드가 하나뿐이므로, 레플리카 샤드를 할당할 대상이 없어 복제본 샤드 수를 0으로 설정하였습니다...ㅎㅎ

PUT /article/_settings
{
"index": {
"number_of_replicas": 0
}
}

검색 기능 개발은 다음 게시물에...
'데이터 > 데이터베이스' 카테고리의 다른 글
| [ElasticSearch] ElasticSearch 개념 정리 (0) | 2024.10.24 |
|---|---|
| [Database] DB Lock의 종류와 DeadLock (0) | 2024.08.19 |
| [Database] Index(인덱스)와 최적화 (0) | 2024.08.02 |
| [Database] MySQL User 생성 (0) | 2024.07.24 |
| [Database] DB Session & Connection (0) | 2024.07.24 |